对于有志于进入人工智能领域的初学者而言,常面临一个关键抉择:从何处入手?传统上,人工智能涵盖机器学习、专家系统、知识图谱、自然语言处理等多个分支。以深度学习为代表的技术路径,因其独特的优势,已成为许多人入门人工智能并切入基础软件开发的优选起点。这并非意味着其他分支不重要,而是深度学习提供了一个相对集中、实践性强且生态成熟的切入点。
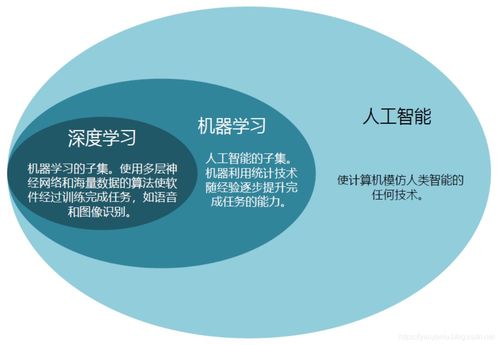
深度学习的理论框架与核心概念,为理解现代人工智能提供了直观的桥梁。深度学习本质上是机器学习的一个子集,其核心是使用包含多个层级(“深度”)的人工神经网络来学习数据的层次化特征表示。相较于一些更传统的机器学习方法(如支持向量机、决策树),深度学习的模型结构(如前馈网络、卷积神经网络CNN、循环神经网络RNN)具有更强的表现力和拟合复杂函数的能力。初学者通过学习这些基础模型,能够快速建立起对“模型”、“训练”、“推理”、“损失函数”、“优化器”等关键人工智能概念的具象理解。这种从具体模型入手的学习路径,比一开始就陷入更抽象的数学理论或宽泛的AI哲学讨论,更容易获得正向反馈和持续动力。
深度学习的实践与软件开发流程紧密结合,提供了从理论到代码的清晰路径。现代深度学习高度依赖于编程和软件开发技能。以Python语言为核心,辅以强大的开源框架(如TensorFlow、PyTorch),构成了一个极其活跃和友好的开发环境。初学者可以很快地安装一个框架,跟随教程,用几十行代码搭建一个神经网络,在标准数据集(如MNIST手写数字识别)上完成训练和评估,亲眼看到模型从“不会”到“学会”的整个过程。这个过程完美地模拟了AI基础软件开发的典型流程:环境配置、数据加载与预处理、模型定义、训练循环、评估与部署。通过这种“做中学”的方式,学习者不仅能掌握深度学习原理,更能同步锻炼其作为AI开发者的核心工程能力,包括代码调试、性能分析和简单的模型部署。
深度学习拥有丰富、成熟且高质量的学习资源与社区生态。从吴恩达的《深度学习专项课程》,到斯坦福大学的CS231n(视觉)和CS224n(自然语言处理),再到数不胜数的优秀书籍、博客、开源项目和在线竞赛(如Kaggle),深度学习的教育资源在深度、广度和可及性上都首屈一指。强大的社区意味着初学者遇到的大多数问题都能通过搜索找到解答,这极大地降低了学习门槛。许多AI基础软件工具和平台(如模型训练平台、推理引擎、模型压缩工具)也都是围绕深度学习模型构建和优化的,熟悉了深度学习,就自然能理解和使用这些工具,为后续参与更复杂的AI系统工程打下基础。
从深度学习切入,能自然延伸到人工智能的广阔应用领域。深度学习不仅是理论研究的热点,更是当前AI产业应用的主要驱动力。计算机视觉(图像分类、目标检测)、自然语言处理(机器翻译、文本生成)、语音识别、推荐系统等核心应用领域,其前沿成果大多建立在深度学习模型之上。因此,掌握了深度学习基础,就相当于拿到了探索这些热门领域的钥匙。学习者可以在一个统一的神经网络范式下,通过调整模型架构和训练数据,去解决完全不同领域的问题,这种能力的可迁移性非常强。
必须指出,将深度学习作为起点并不意味着它是人工智能的全部。一个扎实的AI从业者最终需要补充概率统计、优化理论、传统机器学习算法以及特定领域的知识。但对于入门者,尤其是那些对AI基础软件开发感兴趣的人而言,深度学习提供了一个目标明确、路径清晰、资源丰富且充满成就感的起点。它成功地将复杂的智能问题,转化为可编程、可训练、可迭代的软件模块,让“创造智能”这一宏大命题,变得触手可及。从这个意义上说,从深度学习开始人工智能之旅,无疑是一条高效且务实的路径。